 取材・お問い合わせ
取材・お問い合わせ メディア掲載実績
メディア掲載実績日本の子供たちが、英語を身につけて ミライに羽ばたくために。
日本の子供たちが、英語を身につけて ミライに羽ばたくために。
2022.09.02

「英語で会話する機会がない」。これは、日本で英語を長年学んでもなかなか話せるようにならない理由としてよく挙げられます。学校の英語教育でも、情報や考えなどを即興でやり取りする力を育てることは課題の一つです。今回は、テクノロジーがこの課題を解決できる可能性について考えるべく、会話AI技術による英語スピーキング能力判定システムなどの研究開発に取り組む松山 主任研究員と鈴木 次席研究員(早稲田大学GCS研究機構)にお話を伺いました。会話AIの技術や仕組み、第二言語習得の理論、英語教育のあり方など、さまざまな観点から、会話AIの課題や可能性について2回に分けて紹介します。
前編となる今回は、主に、英語学習・英語教育で役立つために解決されるべきAIの課題についてです。
著者:佐藤 有里
まとめ
・生徒や教師がAIの判定結果に納得して学習・指導に活かすためには、「AIがなぜそう判断したか」を説明できる仕組みが重要。
・会話AIには、スピーキング能力の判定による自己学習のサポート、人間にしか教えられないことに教師が集中できる環境づくり、インタラクティブな会話を学べる体験の提供など、さまざまな可能性がある。
・社会的スキルを持つ会話AIの研究開発によって、コミュニケーション能力のあり方について理解が深まることが期待される。
【目次】
―松山先生・鈴木先生は、早稲田大学 GCS研究機構のプロジェクト「人と共に成長するオンライン語学学習支援AIシステムの開発」の共同代表を務めていらっしゃいます。どのようなプロジェクトですか?
松山先生:
国の研究機構であるNEDO(新エネルギー・産業技術総合開発機構)から委託されて2020年度から取り組んでいます。NEDOでは、「人と共に進化する次世代人工知能に関する技術開発事業」という大きなプロジェクトが2020年度から始まっているのですが、これから人とAIが共存していく世界を考えるうえで、人とAIが共に進化する(共進化)というモデルをどのように社会実装するか、ということがテーマになっています。
我々のプロジェクトは、その中でも教育のドメイン(領域)であり、「説明可能なAI」の開発が大きな目標です。
―「説明可能なAI」とはどういうことでしょうか?
松山先生:
AI技術でいろいろなことができるようになってきて、AIが何かを判断する能力も上がってきました。一方で、AIはどうしてそのような判断をしたかは言えないので、そのプロセスはブラックボックスになりがちです。
「end-to-end機械学習」と呼ばれているのですが、終端(どのような情報を入れたか)と終端(どのような結果が出たか)はわかるけれど、その結果が出たプロセスはわからない、ということです。
AIで何か結果が出たとしても、なぜかはわからないし責任ももてないとなると、結局「使えない」ということになるので、理由を説明できることが重要なんです。
―教育の分野でAIを活用するときに、説明可能であることはなぜ重要でしょうか?
松山先生:
教育の分野では、判定結果を説明できるということは大事だと思っています。病院で何か診断されたときも、丁寧に説明してもらえると納得感があって結果を受け入れやすいのではないでしょうか。
AIが何か能力を判定したときには、なぜそうなったのか(現状分析)、次はどうすればいいのか(学習提案)、ということを説明可能にしたいと考えています。
そこから生まれたのが「InteLLA(Intelligent Language Learning Assistant /言語学習支援エージェント)」というAIシステムです。AIが10分間くらいの会話をして、CEFR(※1)を基準に英語のスピーキング能力を判定します。
我々のミッションは、AI技術を活用することによって、学習する側にとっても教育する側にとっても「納得感のある」語学学習支援の仕組みをつくることです。InteLLAはまだ始まりで、これからもっと大きなプロジェクトになっていきます。

InteLLAによる英語インタビューの様子
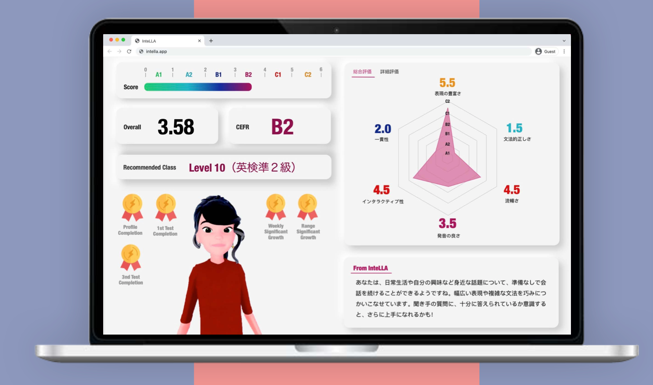
CEFRに基づき、6つのカテゴリでスピーキング能力が評価される
―では、InteLLAについて詳しく教えてください。どのような仕組みのシステムでしょうか?
松山先生:
InteLLAというシステムを動かすための柱は、三つあります。
まず、データを集めるようなエコシステム(データ・インフラ)。そして、能力判定システム。最後に、Human-in-the-Loop機械学習システムです。
Human-in-the-Loop機械学習は、機械学習の中に人を入れて、人とAIが一緒に学習していくことで精度を上げようとする技術で、最近はいろいろな企業で活用されるようになりました。
AIの能力判定はやはり完璧ではないので、人間がAIを助けながらだんだん賢くしていく、というパラダイムを考えています。AIが自分の判定結果に自信がもてない(確信度が低い)ときは、人に判定を求めるような仕組みにすることで精度を担保して、能力判定のスピードと品質を両立させようとしています。
我々の専門は、対話システムです。インタラクティブな会話を実現するために、AIが相手のことばの意味を理解したり、自分でことばを生成したりする仕組みですね。その会話で得られたデータをもとに能力を判定するのですが、この判定結果が出たのはなぜかということをある程度説明できるようにするための仕組みをつくろうとしています。
―AIによる判定結果の理由を説明できるようにするために、どのような工夫がされているのでしょうか?
松山先生:
InteLLAのインタビュー・システムは、基本的にACTFL-OPI(Oral Proficiency Interview)(※2)の考え方に則ってつくっています。
例えば、はじめは簡単な話をしながら大まかなレベルを把握して「この人はCEFR A2レベルの会話でスタートかな」という判断をします(ウォームアップ)。そして、A2レベルの質問をしてみて「できるな」と思ったら(レベルチェック)、あえて一つ上のB1レベルの質問をします(プローブ)。そのときに相手の発話が滞ったら(ブレイクダウン)、「元のレベルに戻ろう」という判断をします。
こういう判断を繰り返しながら会話を続けて、最終的に能力を判定するんです。発話のターンが増えて、データサンプルを集めれば集めるほど判定結果の精度は上がっていくのですが、15ターンくらい(約2〜3個の会話トピック)すると、だいたいレベルがわかってくるということが実験でわかっています。
このように、InteLLAでも会話の戦略を決めて、逐次的に能力を判定できるようにしています。
―AIが相手の発話や反応に合わせて質問の難易度を変えていくんですね。
松山先生:
はい、通りいっぺんの質問をするのではなくて、「どのような発話データがあれば、この人の能力の上限と下限がわかるか」、「A2レベルかB1レベルかで判断を迷うから、その辺の発話データを十分とったほうがいい」、「流暢性についてもうちょっと知りたいから、この質問を投げかけよう」ということを判断しながら質問します。
このようにAIのほうからうまく発話を引き出すという機械学習は、意外とありません。能力判定の根拠となる発話を引き出すことで、「ここがこうだったから、こういうデータをとったんです」というふうに、どのようなプロセスでデータを得たかがわかるので、能力判定の説明性が上がります。
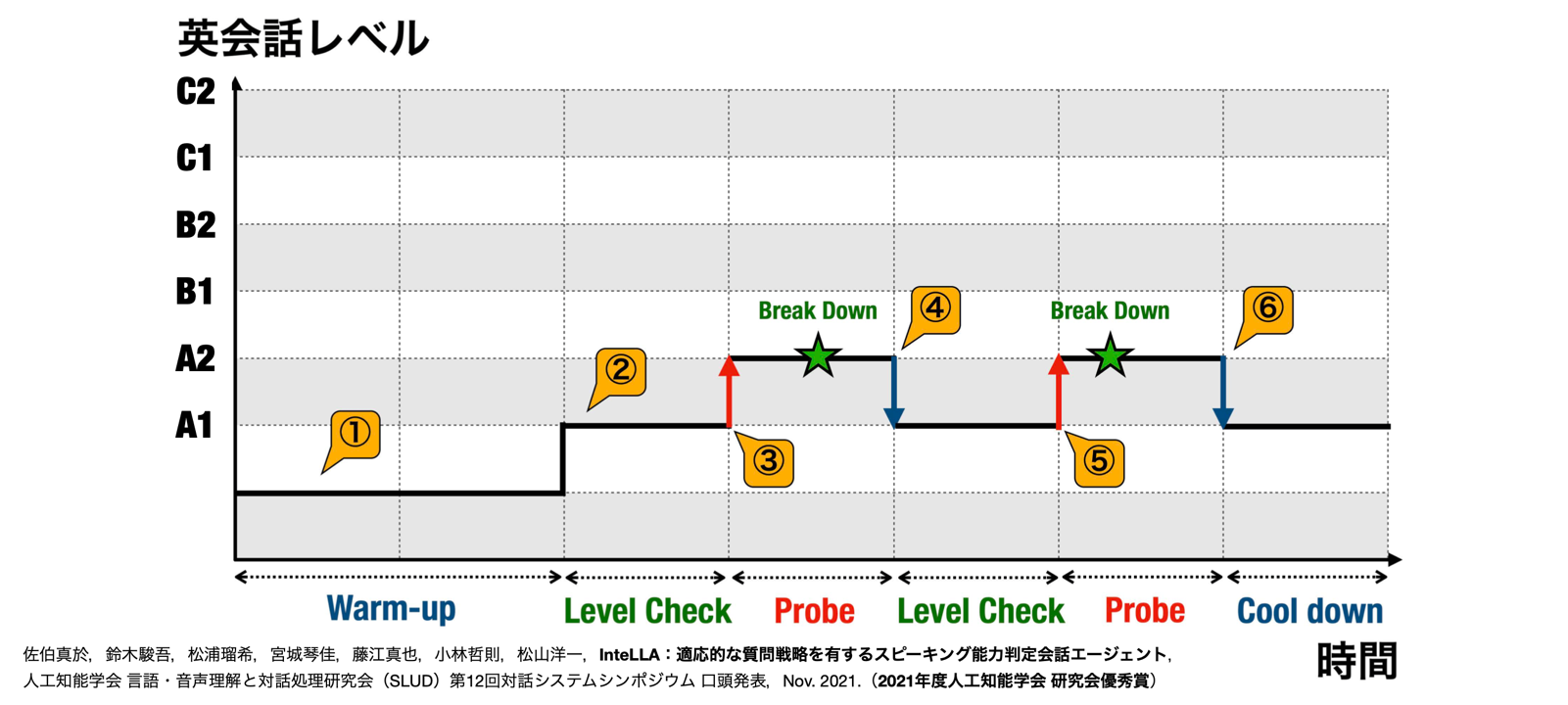
Breakdown(ブレイクダウン):言語的挫折。受験者が質問を理解できなかったり言語能力が不足していたりすることで会話が滞ること(言い淀みや沈黙など)。
Probe(プローブ):突き上げ。AIエージェントが現在の推定レベルより一つ上の難易度の質問を行うこと。
(佐伯ほか, 2021)
―InteLLAでは、相手のどのような情報をとって英語力のレベルを推定しているのでしょうか?
鈴木先生:
音響情報、語彙や文法などの言語情報、振る舞いや視線などの画像情報など、マルチモーダルな情報を取とっています。
いろいろな技術であらゆる情報をとれますが、その中から第二言語習得の理論に基づいて「こういう特徴だったら測りたいものを測れるだろう」という情報を選んでいます。
ただ、理論に基づいて厳密に選んでも、多くの先行研究同様に判定結果の60〜70%くらいしか説明ができません。ですから、未知の部分については、ほかの情報も探索的に入れながら検証しています。
例えば、インタラクション(やり取り)の力をどういった特徴で測れるかということは、まだはっきりとわかっていません。会話のゴールに向かってきちんと話をまとめているか、会話のやり取りが均一・双方向になっているか、など、実は第二言語習得の分野でも定義があいまいです。ですから、インラクションの能力を再定義するための研究も進めています。
―例えば、発話が滞ったということは、現状どのような情報で判断されますか?
松山先生:
発話が流暢でないところ(ブレイクダウン)は、自然言語処理や音声処理など、最新の機械学習の技術をたくさん使って、話速(発話時間1秒あたりの音節数)やポーズ頻度(発話時間に対する無音区間の割合)などのデータによって検出できるようになってきています。
ただ、あるトピックでAIが質問を投げかけて発話が何かしら滞ったとき、質問が理解できていないのか、理解できているけど発話の生成がうまくいっていないのか、という理由がわかるデータもとりたいと考えています。
―発話が滞った理由がわかるデータは、なぜ重要なのでしょうか?
松山先生:
例えば、発話のあとに無音が続くとします。この無音をどういうふうに解釈するかによって、InteLLAが次に言うべきことが変わるからです。
「質問の意味は理解できていて答えを考えている」という状態であれば、ある程度待ってあげる必要がありますよね。でも、質問の意味が理解できていないのであれば、質問を別のことばで言い換えてあげたりする必要があります。いまは視線の向きなどの画像処理のデータを捉えながら推定する、という検証をしています。
そういう細かなデータをとりながら発話戦略を変えていく、ということが会話技術の本質的な部分なのでトライしているのですが、個人差も大きいので難しいです。
―ことばや行動だけではなく、その意図を理解する必要があるということですね。
松山先生:
会話を成り立たせるためには、いろいろな能力が必要ですよね。
会話のあり方は、どのタイミングで何を言うか、どこでどれくらい発話が滞ったか、誰を相手に話すか、ということなどによって変わってくると思います。
この瞬間にこの言い方をしたということは、ことばの意味とは違う、何か社会的な意味があるに違いない、みたいな判断もできないと、会話は自然になりません。こういうこともうまくバランスよくデザインしてはじめて会話AIができると考えています。
―機械学習は、とにかくたくさんの情報を入れればよいというイメージがありましたが、判定結果の説明性を高めるためには、どのような情報を選んでとるか、ということがとても重要ですね。
松山先生:
一般的に、機械学習では、正確性(判定結果がどれくらい正確か)と説明性(判定結果をどれくらい説明できるか)はトレードオフの関係にあります。
いまの技術であれば、音声や映像など、可能な限りあらゆる大量の情報を機械学習に入れることが正確な判定結果を出せる可能性が一番高まります。
でも、理論的に流暢性と関係があると言われている特徴を選んで、それを入力して結果を出せば、どの特徴がどの意思決定に効いたかということがわかるので、判定結果の説明性が上がります。
第二言語習得の知見に基づいて、データがどのように流れるかという構造をある程度つくり込むと、入力する情報が少なくなるので判定結果の正確性が若干下がる可能性はあるのですが、正確性と説明性を両立できるといいなと考えています。これは機械学習の課題ですね。
鈴木先生:
自動採点を使わないテストでも、標準誤差という考え方があります。テストのスコアは正しいように思えますが、どのテストも±(プラスマイナス)のブレがあるんです。
例えば、TOEICだったら35点くらい幅があって、本来のスコアが900だったとしたら、930になる可能性もあれば870になる可能性もあります(※3)。
テストはそもそも、それくらい結果がばらつくものなので、正確性を高めるという点では、我々は無理難題に取り組んでいるわけです。
でも、InteLLAの判定結果をクラス分けに使う場合、生徒は、本来よりも上のレベルのクラスに入れられてしまうと難しすぎてうまくやっていけない。逆に、本来よりも下のレベルのクラスに入ってしまうと簡単すぎてつまらなくなってしまう。そうなると、先生方も授業をやりづらいですよね。
ですから、AIを活用して学習者や教師をサポートするためには、ある程度の精度が必要です。かつ、どういう学習をすればいいか、どういう授業をすればいいか、という情報を提供するためには、なぜその判定結果になったかという理由を説明できる必要があるんです。
―英語を学んでいる人や教える人にとって納得感のあるAIシステムをつくる、ということは、とても難しいことがわかりました。会話AIを専門とする松山先生は、なぜこの難題に取り組み始めたのでしょうか?
松山先生:
私は、AIと人の自然な会話を実現することが研究者としてのミッションです。この会話AIについて研究する中で、今後5年、10年、社会のどのような領域でAIが発達していくかということを考えたときに、英会話という分野がおもしろいと思いました。
英会話は、教えるときにも学ぶときにもいろいろな能力が問われますよね。いろいろな会話タスクの中でデータを集めて鍛えていけば、おもしろい会話AIになるだろうと想像できたんです。
当時はアメリカの大学に5年くらいいたのですが、英会話のAIを研究して社会実装することを目指すなら日本に戻ろうということで、3年前に帰国しました。
機械学習はデータを入れれば動くので、自分でCEFRの本を読んで勉強しながら「とりあえずデータを入れて結果を出してみよう」というふうにトライするところから始めましたね。
その後、言語テストについて研究されている澤木泰代先生(早稲田大学 教授)を通じて、鈴木先生に巡り合いました。
―鈴木先生は、第二言語習得の中でもスピーキングのメカニズムについて研究されてきたとのことです。なぜ、この会話AIのプロジェクトに参加されたのでしょうか?
鈴木先生:
人間が発話をするメカニズムはなんとなくわかってきたけれど、それはどれだけ学習者にとって意味があるのだろうか、ということを考えたときに、いままでやってきた「事象の理解」という研究だけではなく「知見の応用」という研究をしたいと思いました。
「あなたの強いところと弱いところはこういうところだから、次はここを勉強すれば次のステップに進めますよ」ということがわかるような言語テストについて研究できるポストを探していたところ、澤木泰代先生からこのプロジェクトを紹介されたんです。
こんなに会話AIの技術が進んでいることに驚いて、私のほうから松山先生に熱烈なアピールをして去年(2021年)の秋からこちらのプロジェクトに携わることになりました。
―鈴木先生がプロジェクトに加わることで、どのような変化がありましたか?
松山先生:
以前は会話AIを動かすということで精一杯で、技術寄りのプロジェクトだったのですが、鈴木先生が参加したことで、プロジェクトの着地点が「人の成長」になり、技術をどのように活かせるかがわかってきました。この変化は大きかったですね。
私は比較的つくることが好きで得意な人間ですが、彼は事象を理解することに情熱をもっているので、「つくりながら理解する」というサイクルがまわりやすいです。
実は、第二言語習得の観点から能力判定テストをつくることは、会話AIをつくることと極めて近いんです。会話AIの研究は、相手のどのような特徴の情報をとって、どのように意味を理解して、どのような発話を生成するかを考えることですが、言語習得の学問的な体系がとても役に立ちます。人の言語能力をどのように考えるか、という理論をそのまま会話AIの設計に活かすことができるので、非常におもしろいです。
鈴木先生:
第二言語習得という研究分野は、すでにわかっていることがけっこう多いと思っていたのですが、いざ応用してくださいとなると、わからないことだらけなんです。なので、研究そのものを進めるうえでも、何か応用する場があるというのは、学術的にとても健全だと思っています。
もし応用する機会がなかったら、いろいろなことを見過ごしていたかもしれません。つくってみてうまくいかなければ、理解したと思っていたことが幻想だったとわかるので、認識を改めなければいけないということになります。「つくる」と「理解する」というサイクルをまわせることは、研究者としてすごく魅力的に感じます。
(※1)CEFR:Common European Framework of Reference for Languages: Learning, teaching, assessmentの略。外国語の学習、教授、評価のためのヨーロッパ共通参照枠。20年以上にわたる研究を経て、2001年に欧州評議会が発表した、外国語の学習者の習得状況を示す際に用いられる枠組み。語学シラバスやカリキュラムの手引きの作成、学習指導教材の編集、外国語運用能力の評価のために、透明性が高く、わかりやすい、包括的な基盤を提供するもの(Council of Europe, 2001; 文部科学省, 2018a)。
(※2)ACTFL(全米外国語教育協会)が開発した、口頭インタビューによって言語能力を測るテスト(ACTFL, 2022)。
(※3)Educational Testing Service (2022). Score User Guide: TOEIC Listening & Reading Test, Paper Delivered. Retrieved from
https://www.ets.org/s/toeic/pdf/toeic-listening-reading-test-user-guide.pdf
【取材協力】

早稲田大学 GCS研究機構 知覚情報システム研究所 松山 洋一 主任研究員(研究院 准教授)
研究ミッションは「社会的知能を有する会話AIメディアの実現」。早稲田大学 基幹理工学研究科 情報理工学専攻 博士後期課程にて博士号(工学)を取得。イタリア工科大学 認知ロボティクス研究室客員研究員、米国カーネギーメロン大学ヒューマン・コンピュータ・インタラクション研究所および言語技術研究所 博士研究員を経て、2019年より現職。さまざまな会話AI産学連携プロジェクトを主導してきた経験を持つ。国立研究開発法人 新エネルギー・産業技術総合開発機構(NEDO)「人と共に進化する次世代人工知能に関する技術開発事業」に採択された「人と共に成長するオンライン語学学習支援AIシステムの開発」の研究代表(2022年度より鈴木研究員と共同代表)。2022年5月2日には、同研究チームを中心に早稲田大学発スタートアップ「株式会社エキュメノポリス」(https://www.equ.ai)が創業され、代表取締役を務める。

早稲田大学 GCS研究機構 知覚情報システム研究所 鈴木 駿吾 次席研究員(研究院 講師)
専門は、外国語教育、第二言語習得。質の高い発話とは何か、第二言語での発話はタスクの難易度や性質に応じてどのように変わるか、第二言語学習者が流暢に話せるようになるためにはどのような言語知識が必要か、といったテーマで研究を行う。英国ランカスター大学にて博士号(言語学)を取得し、2021年より現職。ランカスター大学 言語学部 客員講師、早稲田大学 文学学術院 非常勤講師も務める。早稲田大学 GCS研究機構の語学学習支援プロジェクト「人と共に成長するオンライン語学学習支援AIシステムの開発」の共同代表を務め、能力判定システムの研究開発チームを率いる。同研究チームが開発した「InteLLA」は2021年に世界最大の教育コンテスト「the QS-Wharton Reimagine Education Award」で表彰されている。早稲田大学発スタートアップ「株式会社エキュメノポリス」のリサーチ・サイエンティスト。
<InteLLAの紹介動画>

■関連記事
ACTFL(2022). Oral Proficiency Interview (OPI). Retrieved from https://www.actfl.org/assessment-research-and-development/actfl-assessments/actfl-postsecondary-assessments/oral-proficiency-interview-opi
Council of Europe (2001). Common European Framework of Reference for Languages: Learning, teaching, assessment. Cambridge University Press. Retrieved from
Council of Europe (2020). Common European Framework of Reference for Languages: Learning, teaching, assessment – Companion volume. Council of Europe Publishing. Retrieved from https://rm.coe.int/common-european-framework-of-reference-for-languages-learning-teaching/16809ea0d4
国立教育政策研究所(2019).「平成31年度(令和元年度)全国学力・学習状況調査 報告書 【中学校/英語】」. Retrieved from
http://www.nier.go.jp/19chousakekkahoukoku/report/19middle/19meng/
佐伯 真於, 松浦 瑠希, 鈴木 駿吾, 宮城 琴佳, 小林 哲則, 松山 洋一(2021).「InteLLA:適応的な質問戦略を有するスピーキング能力判定会話エージェント」.『人工知能学会研究会資料 言語・音声理解と対話処理研究会(第93回) ―第12回対話システムシンポジウムー』, p.15-20.
https://doi.org/10.11517/jsaislud.93.0_15
文部科学省(2017a).「中学校学習指導要領(平成29年告示)解説 外国語編」. Retrieved from
https://www.mext.go.jp/content/20210531-mxt_kyoiku01-100002608_010.pdf
文部科学省(2018a).「各資格・検定試験とCEFRとの対照表」.
https://warp.ndl.go.jp/info:ndljp/pid/11293659/www.mext.go.jp/b_menu/houdou/30/03/__icsFiles/afieldfile/2019/01/15/1402610_1.pdf
文部科学省(2018b).「高等学校学習指導要領(平成30年告示)解説 外国語編 英語編」. Retrieved from
https://www.mext.go.jp/content/1407073_09_1_2.pdf