 取材・お問い合わせ
取材・お問い合わせ メディア掲載実績
メディア掲載実績日本の子供たちが、英語を身につけて ミライに羽ばたくために。
日本の子供たちが、英語を身につけて ミライに羽ばたくために。
2018.08.01

近年は高精度な翻訳アプリやソフトが世界中で開発され、テレビや新聞・雑誌、ソーシャルメディアなどでは「外国語を学ばなくてもよい未来がくるのでは」、「翻訳者や通訳者が不要になるのでは」という意見が見受けられます。
しかしながら、外国語や言葉に関わる職業の人々や専門家の多くが「人間にしかできない翻訳・通訳がある」という見解を示しています。
【目次】
NTTデータ経営研究所(2017)が実施した調査によると、都市部の企業(従業員規模100名以上)で働く20代〜50代のオフィスワーカー948人のうち約9割は、手順やルールが決まった業務はシステムやAI、ロボットなどによって代替されると考えていることがわかりました。一方、「自動化できる」と考える人が最も少なかった業務5つは、以下の通りです。
| 1. 部下や後輩の育成 10.9% |
| 2. 他社とコミュニケーションをとりながら進める業務 19.8% |
| 3. 相手の意図を汲み取り、臨機応変に対応する業務 20.5% |
| 4. 新しいアイデアや工夫する点を考える業務 20.7% |
| 5. 前例のない課題に答えを出す業務 21.1% |
参考:NTTデータ経営研究所(2017).「AI/ロボットによる“業務代替”に対する意識調査」. http://www.keieiken.co.jp/aboutus/newsrelease/170720/supplementing01.html#result
この調査結果を見ると、「人とのコミュニケーション」は自動化できないと考える人が極めて多いと考えられます。しかしながら、NTTデータ経営研究所は、AI技術の進歩により「自動化される可能性は充分にあるはず」と、世論が楽観的であることを指摘しています。では、母語の異なる人同士の情報伝達やコミュニケーションを助ける翻訳や通訳といった職業もAIに取って代わられるのでしょうか?
スマートフォンやパソコンを使って簡単に外国語を翻訳したり外国人と会話したりできる、翻訳アプリや翻訳ソフト。世界的には、103もの言語に対応するGoogle翻訳が有名であり、タイピングした文字、手書き文字、撮影した文字、音声など、さまざまな方法で言語を認識することができ、瞬時に希望する言語へ翻訳します(Google, 2018)。
日本では、2015年以降の約3年間だけでも多くの翻訳アプリや翻訳ソフトが開発されており、以下はその例です。
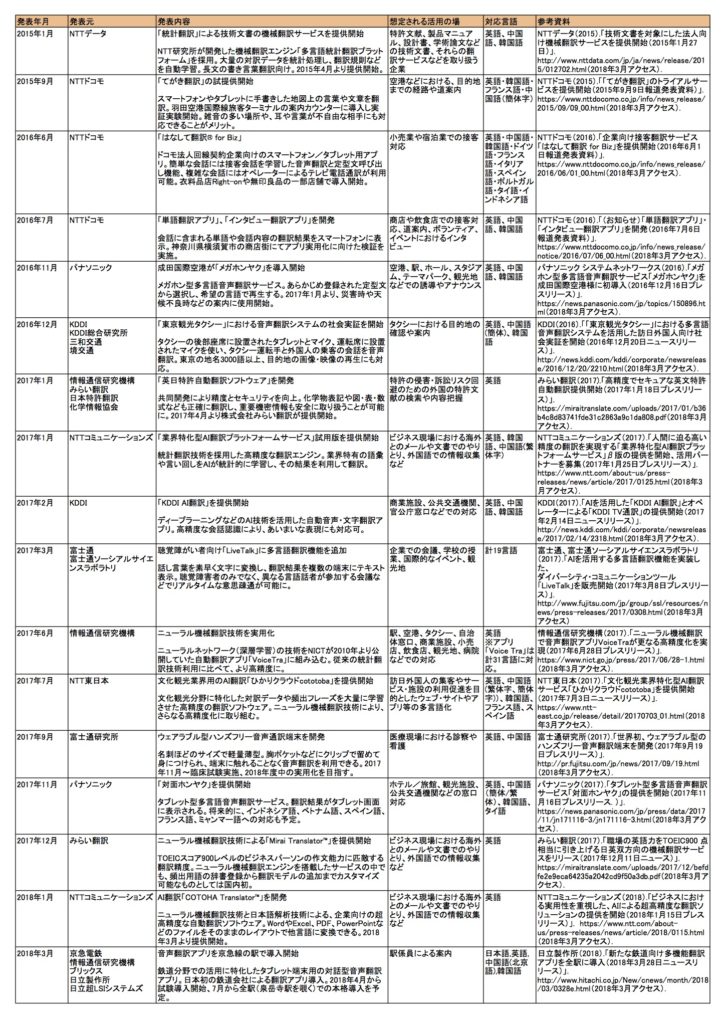
機械による翻訳は文章が不正確または不自然、という認識をもつ人は多いのではないでしょうか。しかしながら、機械翻訳技術は、以下の通り3つの段階を経て大きく発展してきており、不正確、不自然という課題は徐々に克服されつつあります。
【第一世代】ルールベース翻訳
「この単語は、こう訳す」、「この特徴があれば、こうする」など、文法規則や辞書に基づいた翻訳のルールを人間がつくり機械に教えます。言語の専門家が不可欠なため、開発コストや時間がかかり、専門家が確保できない言語には対応が難しいと言われています(塚田 et al., 2007)。
【第二世代】統計翻訳
大量の対訳データ(例:This is an apple./これはりんごです。)を機械に与え、「この単語は、高い確率でこう訳される」、「この場合は、高い確率でこの語順に並び替えられる」というような統計的な分析により、新たな文の翻訳を自動推定することができます。インターネット普及により対訳データの大量収集が可能になったことが後押しとなり、2001年ごろから大きく進展した技術。
専門家がいなくても、対訳データがあれば多言語対応の高精度な翻訳システムをつくることができますが、対訳データの量や質、コンピューター計算の性能によっては精度が低くなる場合があることが課題とされています。日本では、技術文書や公文書など、すでに大量の翻訳データがある分野において特に活用されています(塚田 et al., 2007; NTTコミュニケーション科学基礎研究所, 2018)。
【第三世代】ニューラル機械翻訳
2014年に提案された新しい技術で、「ニューラル」は日本語で「神経」という意味。膨大な対訳データからパターンや特徴を見つけ出し、翻訳に必要な知識と判断力を機械が自ら身につけることができる、まるで人間の脳神経ネットワークのような技術です(中澤, 2017)。
2006年〜2007年に「ディープラーニング(深層学習)」と呼ばれるコンピューター計算の手法が発表され、Googleはこの技術を大規模な実験により進歩させたことで有名です。Googleが2012年に発表した論文によると、1,000台ものコンピューターを使用し、Youtube動画からランダムに選出された1億個の画像をもとに、何の予備知識・情報も与えずに、3日間でネコの顔の特徴を見つけ出させることに成功しました(Le et al., 2012)。
この研究はGoogle翻訳の基礎となったと言われており、2016年9月、Googleは「Google’s Neural Machine Translation(Googleニューラル機械翻訳)」のシステム開発について論文を発表しました。論文では、いくつかの文章においてはGoogle翻訳が人間のバイリンガル翻訳者に近い翻訳精度を見せたこと、使用人口の多い言語同士では誤訳を従来のシステムと比べて約60%減らすことができたことが報告されています(Wu et al., 2016)。
日本においては、2017年6月にみらい翻訳と国立研究開発法人情報通信研究機構(NICT)がニューラル機械翻訳エンジンを共同開発したことを発表しました(みらい翻訳, 2017)。その後、実用化に向けて開発された翻訳ソフトウェアは、TOEICスコア900レベルのビジネスパーソンの作文能力に匹敵する翻訳精度があると報告されています。
以下は、NICTが紹介しているニューラル機械翻訳による翻訳例の一部であり、従来の統計翻訳と比較するとより自然で正確な文章であることがわかります(表内の「SMT」は統計翻訳、「NMT」はニューラル機械翻訳による翻訳結果を指す)。
| 例1 | 原文 | I’ll wait until the terrace is available. |
| SMT | テラスがあるまで待ちます。 | |
| NMT | テラスが空くまで待ちます。 | |
| 例2 | 原文 | Hunger is the best sauce. |
| SMT | 空腹であれば。 | |
| NMT | 空腹は最高のタレです。 | |
| 例3 | 原文 | Yes, you can’t take a reserved taxi or a pickup taxi. |
| SMT | はい貸切タクシーの送迎タクシーに乗ることはできませんか。 | |
| NMT | はい貸切タクシーや送迎タクシーはご利用いただけません。 |
出典:情報通信研究機構(2017).「ニューラル機械翻訳で音声翻訳アプリVoiceTraが更なる高精度化を実現」.(2017年6月28日プレスリリース)」.
https://www.nict.go.jp/press/2017/06/28-1.html
※上記プレスリリースに含まれる「補足資料:今回の成果の詳細」内の表「改善の具体例」のうち例1〜3を抜粋し引用。

2017年9月、総務省とNICTは、ニューラル機械翻訳技術の高精度化と対応分野拡大のため、「翻訳バンク」の運用を開始することを発表しました。
中央官庁、自治体、企業、各種団体などから1億文以上の対訳データを集積して活用することを目指し、日本全国へデータ提供への協力を呼びかけています(総務省, 2017)。
このように、大学や企業の研究機関のみでなく国を挙げて取り組むことにより、機械が人間と同レベルの翻訳ができるようになる日がさらに近づく可能性があります。
国が主体となる音声翻訳の研究は2007年から本格的に始まりましたが、2020年東京オリンピック・パラリンピックの開催が2013年9月に決定してからさらに勢いを増しています。
2014年4月、総務省は「グローバルコミュニケーション計画」という施策を発表し、産学官の連携により、10億円以上の予算を投じて多言語音声翻訳システムの開発と社会実証を強化することが決定しました。外国人観光客が年々増加する一方、「言葉の壁」により生じるさまざまな問題や機会損失があることを課題とし、2020年東京オリンピックで「外国人が暮らしやすい国」としての日本の価値・魅力を世界へアピールすることを目指しています(総務省, 2014)。
翌年の2015年10月には、この計画の推進にあたり、IT専門の公的研究機関「国立研究開発法人情報通信研究機構(NICT)」と計13の企業が「総務省委託研究開発・多言語音声翻訳技術推進コンソーシアム」という団体を設立し、音声・文字認識や機械翻訳技術、社会実証などを分担して研究開発活動を行うことが決定しました(情報通信研究機構, 2015)。
また、2014年6月に閣議決定された「世界最先端IT国家創造宣言」では、「かつて世界が注目し賞賛した日本の姿はない」と日本経済の低迷や社会問題(少子高齢化や人口減少など)について強い危機感を示し、IT技術を戦略の柱としています。東京オリンピックを日本が世界最高レベルのIT利活用社会であることをアピールしビジネスチャンスをつかむ絶好の機会と捉え、「言葉の壁をなくす多言語音声翻訳システムの高度化」をその方法の一つとして挙げています(首相官邸, 2014)。
実際に、音声認識、翻訳、音声合成、という多様な技術が必要となる自動音声翻訳に関する研究は、他国よりも日本のほうが進んでいると言われています(中村, 2008)。
よって、翻訳アプリの研究開発は、観光業と最先端技術の発展により日本が世界で生き残るための国家戦略の一つなのです。さらに、機械翻訳は、人間が翻訳・通訳をする場合の人件費や労働時間を減らし、企業におけるコスト削減や働き方改革に繋がることも期待されています。
国を挙げて翻訳アプリの研究開発に取り組み、機械翻訳の技術は人間の脳に徐々に近づいてきています。しかしながら、言葉にはデータ化できない情報が含まれており、それらをコンピューターが解読したり表現したりすることは難しいと考えられ、ここに人間のバイリンガルがAIに勝るためのヒントが見られます。
例えば、日本語の方言には、単純に標準語へ置き換えられない語彙が数多くあります。方言の意味を相手に尋ねられた場合、意味の近い標準語のみでなく、具体的な使用場面や状況も説明する人が多いのではないでしょうか。また、喜びや感動、驚き、愛しさ、悲しみ、怒りなどの感情を表現するときには、自分が生まれ育った土地の言葉を無意識または意図的に使う場合もあります。
実際に、ある裁判では、方言で話す原告に対して標準語で話すよう裁判官が注意したところ、「方言が理解できない裁判官には、なぜ裁判を起こしたのかという自分の心を理解することはできないはずだ」と原告が反論したそうです(札埜, 2011)。
これらは、意味の近い標準語があったとしても、それだけでは表現しきれない何かがあるということの表れだと考えられます。その土地の歴史や文化、使う人々の記憶や経験などを背景とした独特のニュアンスは、意味の近い標準語を機械的に示すだけでは伝えることができないのです。日本語の標準語と方言の間でさえ完全な言い換えが難しいのであれば、日本語と外国語の間ではなおさら困難です。
海外の書籍や映画のタイトルの多くは、単純に別の言語で言い換えたような訳ではありません。例えば、ハリウッド映画としてリメイクされたことで有名な邦画「ハチ公物語」。アメリカ版のタイトルは「HACHI: A Dog’s Tail(直訳すると、ハチ:犬のしっぽ)」。
さらに、この映画が日本に逆輸入された際の邦題は「HACHI/約束の犬」。英語のタイトルのほうは、飼い主に対する犬の感情を「しっぽ」という視覚的なイメージで表し、より犬の目線や立場に近い印象があります。いずれも亡くなった飼い主の帰りを待ち続ける犬の忠実さや人間との絆を表現するタイトルですが、表現方法が異なります。
文学翻訳者アンディ・マーティン氏は、イギリスのオンライン新聞『インデペンデント』で、人間にしかできない翻訳の要素について次のように説明しています(Martin, 2018)。
(要約)翻訳者は言語を訳してはいけない。言語を体験するべきである。
どの言葉も、完全な対訳はない。なぜなら、どの言葉にも、それを発した人間のアイデアや感情、記憶、経験、恐れ、望みなど、目には見えない、データ化することのできない情報が含まれている。
その言葉を発した人物になりきり、あるとき、ある場所で彼らが発した言葉を、別の時と場所で自分の言葉で再表現し復活させる。翻訳は人間関係の構築と同様で、相手を理解する努力をしなければならない。人間を理解し、その人間のことを別の相手に伝える能力においては、機械よりも人間のほうが優位に立つことができる。
アメリカの認知科学者ダグラス・ホフスタッドター氏は、評論誌『アトランティック』で、「翻訳は、ある人間の人生や創造性を描き続ける、信じられないほど繊細な芸術」、「機械翻訳は、言語を解読するが理解はしない」と述べました。ホフスタッドター氏は、Google翻訳を実際に使用した例をいくつか挙げて説明していますが、そのうち、わかりやすい例を一つ紹介します。
「彼らの家の中には、すべてのものがペアで置いてある。彼の車、彼女の車。彼のタオル、彼女のタオル。そして、彼の本棚、彼女の本棚。」
日本語や英語では、「彼の/his」「彼女の/her」、と所有格に男女の区別があります。これを男女の区別がないフランス語に訳す場合、Google翻訳ではどちらも同じ「sa」と言い換えられてしまいました。人間がこの文章を読めば、男女のカップルが一緒に住んでいる家の様子が頭に思い浮かび、フランス語へ訳すときに工夫できますが、機械翻訳では文章が伝えたいイメージや意味がわからなくなってしまうのです。
ホフスタッドター氏は、最後に次のように述べています(Hofstadter, 2018)。
(要約)翻訳は、明瞭さを維持するのみだけでなく、趣やひねり、独自性といった文章のスタイルを感じられるような橋渡しをすること。
翻訳者は、言葉ではなく、言葉で表現されている考えを頭の中にインプットし、イメージや場面、自分の記憶や経験を思い浮かべながら理解し、理解した内容を別の言語で表現する。
機械翻訳技術のベースとなるものは膨大な対訳データですが、「対訳」という概念そのものに疑問を投げかけていると言えます。アイデア、感情、記憶、経験、望み、意図、趣やユーモア。言葉の背景にある目に見えないこれらの情報をすべて数値化できない限り、コンピューターが人間と同レベルの翻訳をすることは困難です。
「人の気持ちを理解するAI」が話題になっていますが、人間の声のトーンや表情、視線や指の動きなどの画像や音声、生体情報が必要であり、読み取ることができる「気持ち」も興味・関心、満足・不満足、緊張やストレス、困っている、悩んでいる、集中しているなど、ごく限られた心理状態です(富士通, 2016)。
よって、言葉の背景にある考えや感情を理解し、さらに別の言語で表現するという真の翻訳技術においては、人間がAIに取って代わられることはないと考えられます。
機械翻訳により、誰でも簡単に海外の人々と意思疎通や情報交換ができるようになってきました。多くの日本人や日本企業にとって人生やビジネスのチャンスが広がるだけでなく、「言葉の壁」による情報不足や誤解などさまざまなトラブルを防ぐこともできます。
しかしながら、やはり言葉を話すことと、表面的な意思疎通や情報交換とは似て非なるものです。詩人の谷川俊太郎氏は、広辞苑大学の講演にて以下のように述べています(広辞苑大学実行委員会, 2018)。
「言葉というものは、辞書的な意味も大事だけれども、実際に生きていく経験によってその言葉を定義していく。これが本当の言葉の定義の仕方だと思う。」
同じ言葉であっても、その言葉がもつ意味は個人の経験によって異なる場合があります。過去に見たこと、聞いたこと、体験したことが、言葉の理解や受け止め方、言葉の選び方、言葉の並べ方に影響を与えます。言葉の意味や選択が正解かどうかを決められるのは、機械ではなく人間です。
例えば、外国語の語彙を増やしたい場合、単語の意味や対訳を暗記するだけでは、機械と同じです。しかし、その単語で表現される状況(考えや感情など)や、その単語を使う適切な状況(時や場所)を理解することは人間にしかできません。外国語でさまざまな物事を見て聞いて体験し、多様な人間の考えや感情にふれることが、言葉の理解や捉え方、表現を豊かにし、「状況」を理解しながら言葉を発することに繋がるのです。
言葉は、人間を表し、人間関係を生み出し、人生を豊かにします。「データ」としてではなく、そのような言葉の本来の姿を考えれば、翻訳アプリはあくまで人間を助ける道具であり、人間のバイリンガルと同じ土俵に上がって優劣を決められるものではありません。いかに状況を理解しながら、異なる言語を話す人と考えや感情を共有し、親しみや信頼、共感といった人間関係を築くことができるか、またはそれを助けることができるかがコミュニケーションであり、それは翻訳アプリには到底できないことなのです。

写真:PIXTA
Google (2018). Google Translate.
https://translate.google.com/intl/en/about/
Hofstadter D. (2018). The Shallowness of Google Translate. The Atlantic.
https://www.theatlantic.com/technology/archive/2018/01/the-shallowness-of-google-translate/551570/
Le, Q. V., Ranzato, M. A., Monga, R., Matthieu D., Chen K., Corrado, G. S., …Ng, A. Y. (2012). Building High-level Features Using Large Scale Unsupervised Learning. Research at Google.
https://research.google.com/pubs/pub38115.html
NTTデータ経営研究所(2017).「AI/ロボットによる“業務代替”に対する意識調査」.
http://www.keieiken.co.jp/aboutus/newsrelease/170720/supplementing01.html#result
NTTコミュニケーション科学基礎研究所 協創情報研究部 言語知能研究グループ(2018).「統計的機械翻訳」.
http://www.kecl.ntt.co.jp/rps/research/innovative/research_innovative03.html
Martin A. (2018). Google Translate will never outsmart the human mind – and this is why. The Independent.
https://www.independent.co.uk/news/long_reads/long-read-google-translate-interpreter-misunderstanding-human-mind-a8209851.html
Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., …Dean, J. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. Research at Google.
https://research.google.com/pubs/pub45610.html
広辞苑大学実行委員会(2018).「【広辞苑大学動画レポート】谷川俊太郎『ことばが生まれるとき』」. 『広辞苑大学』.
https://kojien-univ.jp/archive/74/
首相官邸(2014).「世界最先端IT国家創造宣言の変更について(平成26年6月24日閣議決定)」.
https://www.kantei.go.jp/jp/singi/it2/kettei/pdf/20140624/siryou1.pdf
総務省(2014).「グローバルコミュニケーション計画〜多言語音声翻訳システムの社会実装〜」.
http://www.soumu.go.jp/main_content/000285578.pdf
情報通信研究機構(2015).「「総務省委託研究開発・多言語音声翻訳技術推進コンソーシアム」の設立について(2015年10月26日プレスリリース)」.
https://www.nict.go.jp/press/2015/10/26-1.html
総務省(2017).「『翻訳バンク』の運用開始(2017年9月8日報道資料)」.
http://www.soumu.go.jp/menu_news/s-news/01tsushin03_02000220.html
塚田元、渡辺太郎、鈴木潤、永田昌明、磯崎秀樹(2007).「統計的機械翻訳」. 『NTT技術ジャーナル』, 19(6), 23-25.
http://www.ntt.co.jp/journal/0706/files/jn200706023.pdf
中澤敏明(2017).「機械翻訳の新しいパラダイム:ニューラル機械翻訳の原理」.『情報管理』, 60(5), 299-306.
https://doi.org/10.1241/johokanri.60.299
中村哲(2008).「言葉の壁を越える音声翻訳技術」. 科学技術動向. 89, p.8-19. 科学技術政策研究所.
http://hdl.handle.net/11035/1973
富士通(2016).「AI特集:感性メディア技術 【第3回】進化を続ける人工知能〜人の行動や反応から「気持ち」を汲み取るAI」.『FUJITU JOURNAL』.
http://journal.jp.fujitsu.com/2016/03/22/01/
札埜和男(2011).「裁判所における方言」. 社会言語部門主催講演会資料. 東京外国語大学 国際日本研究センター.
http://www.tufs.ac.jp/icjs/activityreports/2011/20111021.html
みらい翻訳株式会社(2017).「TOEIC900点以上の英作文能力を持つ 深層学習による機械翻訳エンジンをリリース(2017年6月28日ニュース)」.
https://miraitranslate.com/news/313